
I have had a paperless office for years now. I have tried several providers for this, most recently I was with Evernote for a long time, whose service works very well, but I didn't like the fact that I partly load sensitive letters into the cloud to a third-party provider, which is why I am glad that there is now the possibility to achieve the same range of functions with a Synology Diskstation. The advantage of this is clearly that my letters are now stored in the house on my hardware and that the Synology Diskstation does not incur any costs other than the purchase price of the hardware.
In a paperless office, one does without paper documents, but works as far as possible only with the digital version of the documents, mostly PDFs. The advantage is greater efficiency, but also environmental protection. With today's software solutions, you can search your digital documents for keywords in a matter of seconds and can thus access any document at any time without having to search for it in a folder.
A rough overview of the process of my paperless office
The linchpin of my paperless office is my Synology Diskstation. Thanks to the built-in hard drive raid, the Synology Diskstation offers a certain basic protection, which can be further extended with Synology's own backup solutions. I back up my data from my Synology DiskStation to a second location every night, but that is a topic in itself, so I won't go into it here.
On the Synology DiskStation, you need two apps:
- SynOCR
- This is a programme that makes PDF files searchable. OCR stands for optical character recognition, which means that the PDF is searched for text characters and these text characters are then saved in the PDF itself.
- Synology Drive
- PDFs enriched with text using SynOCR can now be searched using the Synology Drive app. Synology Drive searches not only the file name, but also the file content, which is the key to finding all documents quickly.
- Optional: There is still the question of how the documents are scanned and made into PDFs. It is important that all documents to be processed are stored on the Synology Diskstation in a network drive. It doesn't matter how they get there, there are numerous possibilities. Documents that have already been digitised can simply be stored there via a PC. In the simplest case, letters can be scanned with a mobile phone. Probably the best solution is a scanner that scans the letters automatically, i.e. it automatically feeds the letters and then scans both the front and the back (duplex ADF) and then stores the created PDFs on the Synology Diskstation via the network. I myself work with a multifunction printer that has a duplex ADF scanner* and achieve very good results with it.
Installation and setup SynOCR
synOCR is a well-functioning user interface for the Docker container OCRmyPDF. When synOCR is installed, the DOcker container is also installed, so there is little effort involved here.
Since synOCR is not an official package from Synology, it can only be installed via another package manager. However, this package manager is added very quickly:
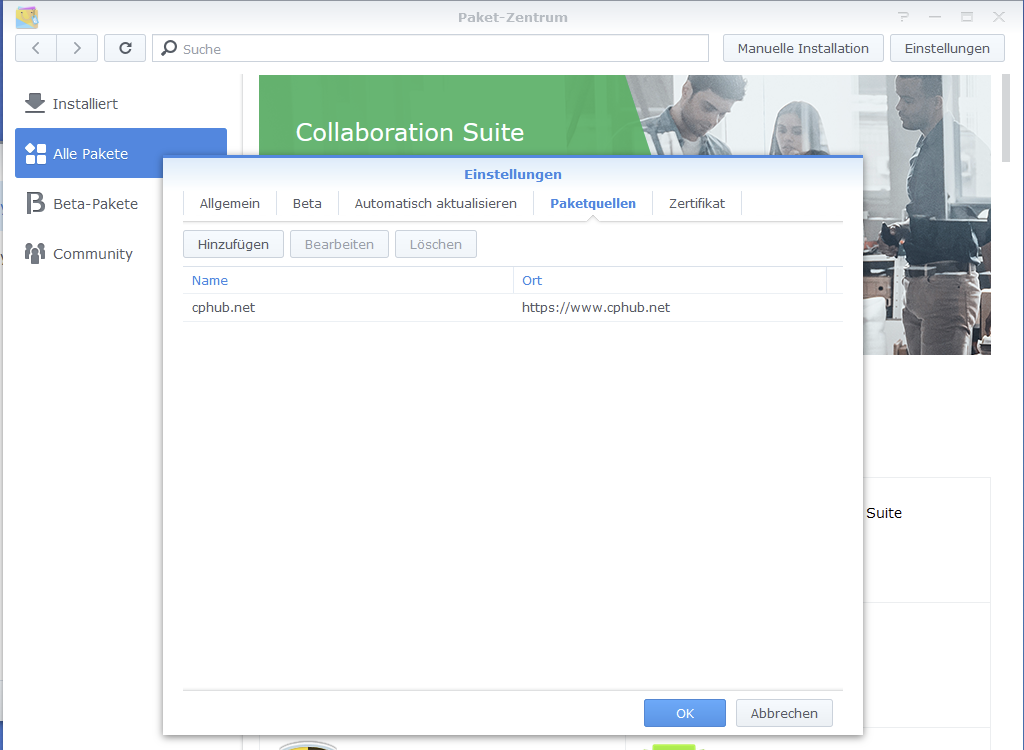
Now the package synOCR can be installed in the package manager under "Community":

Now comes the configuration of the package. To do this, we open the app. The setting options are numerous, but also well described so that you can quickly find your way around. The path settings are particularly important. We need at least one shared folder that serves as the source directory and one shared folder that is to be used as the target directory. Shared folders can be created in the Control Panel -> Shared Folders -> Create. Anyone who can access the target folder can also browse the files in the following step.
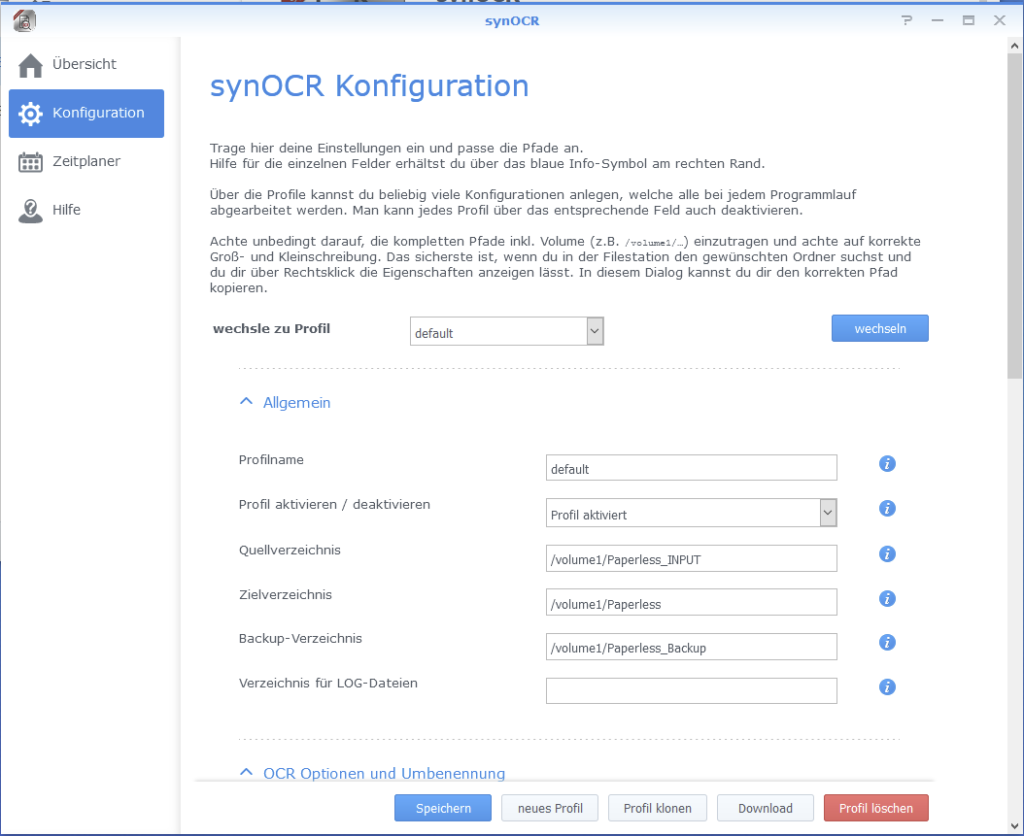
Under "Scheduler" you can set the intervals at which new files are to be searched for. I have decided on hourly. This completes the set-up of synOCR. All files that are now stored in the source directory are searched for texts and then stored in the target directory.
Synology Drive Server Setup
To conveniently browse the target directory, we install the Synology Drive Server:
We now need to tell the Synology Driver Server which directory should be searchable. To do this, we open the Synology Drive Admin Console, select Team Folder and activate the shared folder that we have specified as the target directory:
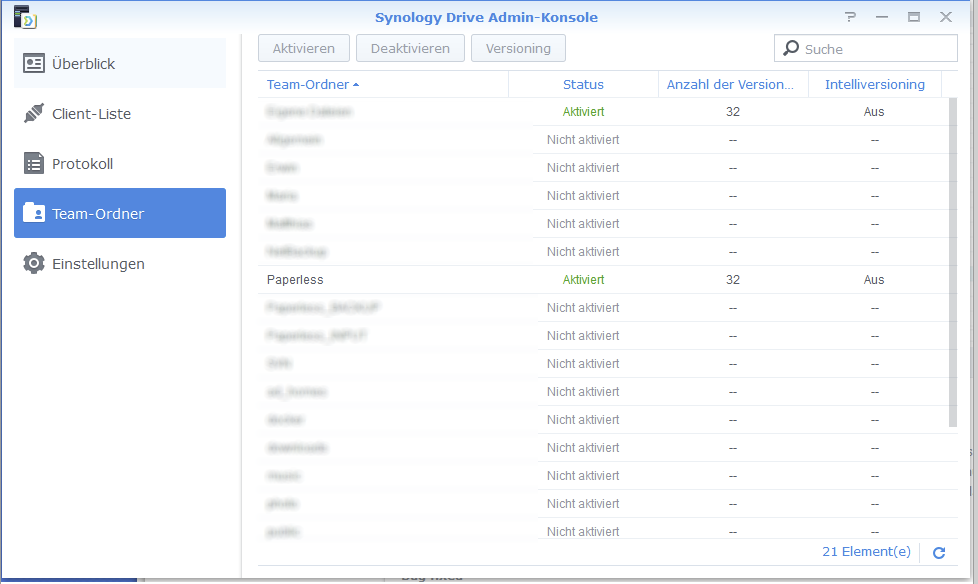
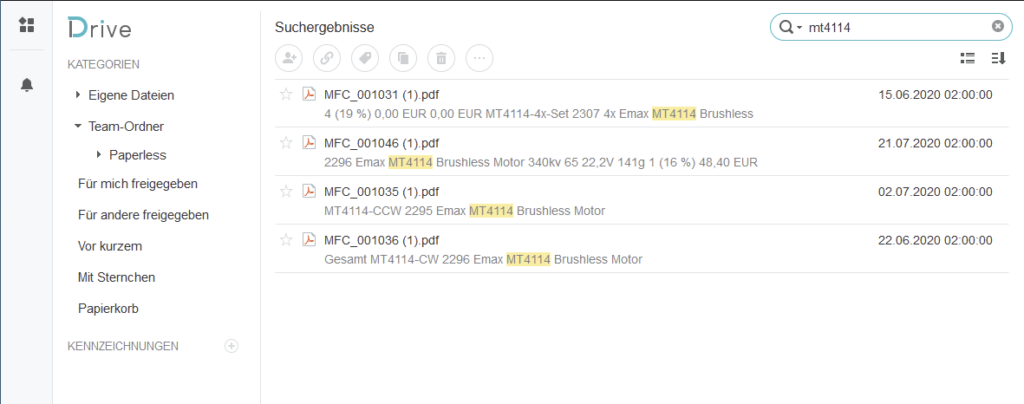
The setup is now complete! The folder can now be conveniently searched with the "Drive Station" app:
Hello Matthias,
Super instructions. I wanted to set it up like this for myself. Unfortunately, I get an error message when setting it up:
"synOCR could not be installed.
Your device (ds118) with CPU architecture aarch64 is not supported by synOCR because the required package Docker cannot be installed (x86_64 only)."
Can I now tick off the topic with me or do I need another Synology?
Thanks for the help.
Greetings
Tobias
Hello Tobias,
Yes, unfortunately you don't have the possibility to install Docker.
Greetings,
Matthias
Docker can be installed on aarch64 devices, but only manually. Some users successfully use synOCR in this way.
Thanks Matthias, with the help of your instructions it worked on my DS218+ right away.
Hi, I'm running, I was looking for something like this. However, I still had to install the container package. I had understood from the description that SynOCR had already integrated it. For me as a DAU, it would have been helpful if there had been a reference to the TAGS to be stored. I managed it anyway.
What about the security of the parcels?
The source code is publicly available for everyone to see.
https://git.geimist.eu/geimist/synOCR
Hello Matthias,
First of all, thank you for the good description.
Unfortunately, I fail with my DS220+/DSM7.0-41222 already because of the authorisation when installing synOCR. The error message says that root rights are necessary for the installation and that this endangers the security of the system.
I should contact the package developer. Is there a way to continue the installation anyway? This topic is still quite new to me...
Thank you in advance!
David
Hello David,
I don't remember getting such a message. I also don't have DSM 7.0 yet, because as far as I know it is still beta. It could therefore also be that synOCR does not run with it yet. I will check when DSM 7.0 has been released as a stable version.
Many greetings,
Matthias
An implementation for DSM7 is planned.
Hello Matthias,
After OneDrive switched off OCR, I looked around for alternatives and found your instructions. Thank you for that.
OCR worked fine, but.... 🙂 ...the documents cannot be searched in the Drive app.
...the documents cannot be searched in the Drive app. If I open the PDF with Adobe Reader, for example, I can search the document perfectly.
Do you have any ideas here?
VG Tobias
Hello Matthias,
sometimes you should approach something with a fresh mind. My problem with the documents not being searched in the Drive app was that you first had to set up in Universal Search that documents should also be indexed in the DMS folder.
Here we go.
VG Tobias
Hello Matthias,
I don't know how to install OCRmyPDF. Do you have any instructions for this?
Vg
Kees
Only the "Docker" package must be installed. synOCR takes care of the rest.
Hello all,
Thank you very much for the detailed instructions. I have just installed SynOCR - and now it is already working on the already existing PDFs. So far, so good. I would now like SynOCR not to start at fixed intervals (and then find no work in 90% of cases), but to become active whenever I scan a new PDF into the input folder. Is that possible?
Many thanks for any tips!
Franz Josef
This is not possible at the moment. However, not much is started - only a small help script that scans the active input directories and, if necessary, starts the actual workflow for new files.
Perhaps folder monitoring will be added in the future ...
Hello,
Thank you for the instructions. Everything works so far. Strangely, my NAS beeps every time synOCR has performed a text recognition and moved it to the target path. Is this normal, or does my disk station crash with every scan?
VG
You can adjust this in the settings in the GUI (at the very bottom) 😉
Information on a DSM7-compatible BETA can be found here: https://www.synology-forum.de/threads/synocr-gui-fuer-ocrmypdf.99647/page-85#post-948365
Hallo
Bei Heise steht in einem Kommentar zu OCRmyPDF, dass alle Daten bei Google ausgewertet werden, stimmt das?
SynOCR verwendet ja OCRmyPDF.
OCRmyPDF verwendet Tesseract.
Und Tesseract verwende angeblich (zumindest in der Basiseinstellung) die Online Texterkennung von Google. Es schickt also alle meine privatesten Dokumente an Google.
Oder kann ich das verhindern?
GR HW